
AWSが落ちてもGCPに逃がすことで落ちないシステムを作る技術
Posted on
こんにちは、エンジニアのtarrです。
KARTE Blocksは既存のサイトにタグを一行入れるだけで、そのサイトを簡単に書き換えたり、ABテストなどで最適化したりできます。
これは、サイトを読み込むときにタグによってBlocks内で設定された内容を反映させているのですが、既存のサイトの挙動に手を加えている以上、一定のリスクが存在します。
今回はそのリスクをインパクトに沿って4段階にわけ、その4つに対してそれぞれ、Blocksがどのように考え、リスクヘッジをしているかを解説します。
後半では、リスクヘッジの施策の一例として、AWSとGCPの両者を使って、サービスプロバイダレイヤーでの冗長構成をとっている仕組みを厚めに説明しています。
この記事は「KARTE Blocksリリースの裏側」の4日目の記事です。全10回を予定しています。
これから毎日記事を更新していくため、更新をチェックしたい方は@KARTE_BlocksのTwitterアカウントをフォローしてください!
「KARTE Blocksリリースの裏側」の記事の一覧です。
- KARTE Blocksを支える技術
- インクリメンタルに新しい技術を取り入れる方法
- セカンドパーティコンテンツをもつサードパーティスクリプトの作り方
- AWSが落ちてもGCPに逃がすことで落ちないシステムを作る技術 ← イマココ
- ユーザーが自ら理解・学習するためのテックタッチなアプローチ
- 爆速で価値あるプロダクトをリリースするためのチームビルディング
- CSS in JSとしてVanilla-Extractを選んだ話と技術選定の記録の残し方
- 0→1のフェーズで複数のユーザー体験をつなぐUIデザインを考える|wagon|note
- リリース後に落ちないように、新規サービスで備えておいたこと
- KARTE Blocksにおけるポジショニングの考え方とその狙い
- 「KARTE Blocksリリースの裏側」の裏側 - 複数人で連載記事を書く方法
なぜリスクヘッジに力を入れるのか
多くのサービスでは、サービスのダウンやバグによる不具合で生じる影響は自社の範囲内で収まります。
最悪のケースとして、自社のサービスでの売上が下がることやユーザーからの不満がたまるなどが予想されます。
当然、セキュリティ的なリスクはもっと大きい被害が出ると考えられます。
リスクにもいろいろな種類がありますが、今回のエントリーではサービスダウンの影響を中心に考えます。
冒頭で触れたとおり、Blocksではクライアントのサイトにサービスの一部(スクリプトタグ)が組み込まれます。
ここになんらかの理由でトラブルが生じた場合、クライアントのサイトへ影響を与えることになってしまいます。
そのため、Blocksチームではリスクを慎重に考え、取れる限りのリスクヘッジを行っています。
Blocksのリスクに対する捉え方として、次の図のように4段階でリスクを考えています。
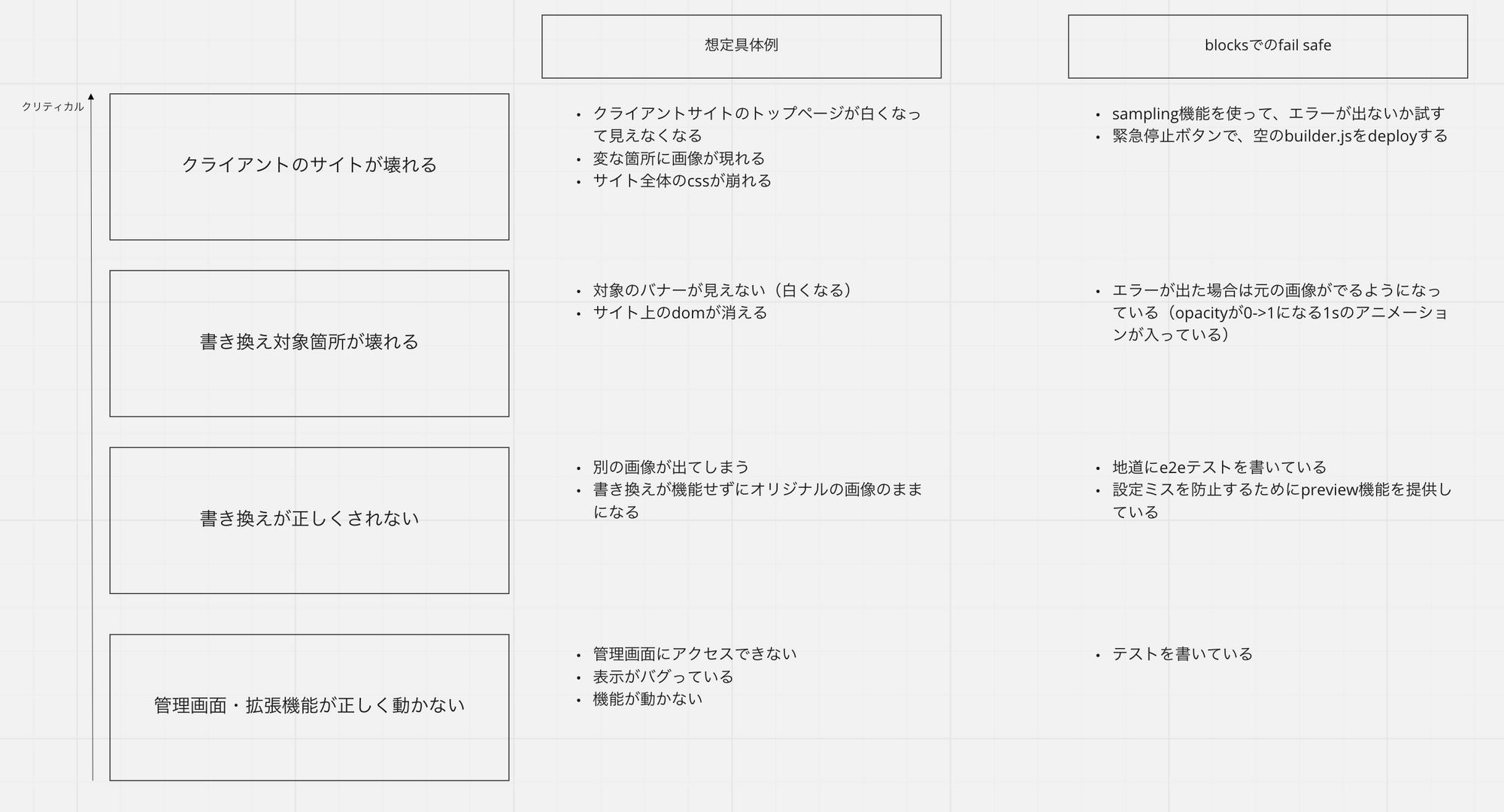
この図は記事のために一部簡略化していますが、社内のドキュメントではより詳細に書かれています。
この記事では、次の4段階のリスクについて、優先度が高い順にそれぞれのリスクと対策を見ていきます。
- クライアントのサイト全体が壊れる
- 書き換え対象箇所が壊れる
- 書き換えが正しく行われない
- 管理画面・拡張機能が正しく動かない
クライアントのサイト全体が壊れる
まず、Blocksチームがもっとも避けなければならないと考えていることが、Blocksのタグを埋め込んだクライアントのサイトが壊れて、クライアントのサービスが機能しなくなることです。
なぜなら、Blocksでコントロールしている外に障害の影響がでてしまい、クライアントに甚大な被害を与えてしまうことになるためです。
Blocksでは、指定したCSSセレクタのDOMに対して、書き換えや効果計測をしますが、ページ全体が見えなくなるなどの影響は起こりにくくなるように設計しています。
Blocksでは埋め込んだタグが壊れて無いかをチェックするために、何重にも防止策を行っています。
具体的には、次のような対策をおこなっています。
- builder.js(読み込まれるタグ)のクロスブラウザテストを行っている
- builder.jsのユニットテストを行っている
- 緊急停止ボタンを設置し、すぐにbuilder.jsの配信を停止できるようにする
- 配信元のAWSのCloudFrontがレスポンスを返さないなどの障害があった場合を想定し、GCPにも冗長構成をとっている(マルチクラウド化)
また、現在では実績をつんだために廃止しましたが、クローズドβの段階では、数%のユーザーのみにbuilder.jsを配信して試すことができるsampling機能も提供していました。
書き換え対象箇所が壊れる
次に考えなければいけないリスクは、Blocksで指定している書き換え対象箇所が壊れることです。
具体的には、Blocksで指定した画像が白くなってしまったり、DOM(Document Object Model)の要素が消えてしまうケースです。
これは、BlocksでDOMの書き換えや効果計測をしているため、問題が起きる可能性は避けられません。
DOMの書き換え時に発生する問題への対策として、ひとつの事例を紹介します。
Blocksでは、DOMを書き換えをする前に、対象の要素を透明化させています。
この処理をしない場合、最初に元の要素が一瞬だけ見えて、Blocksで登録したブロックの要素に書き換えられるため、サイトを訪れたユーザーにはちらついて見えて、体験が悪くなります。
そこで、最初にページをloadする際に、対象の要素を透明化することによって、ちらつきをなくすことができます。
しかし、これにはリスクが伴います。
透明化をさせたあとで、書き換え処理を行う際に何らかのエラーで処理が止まってしまった場合、元の要素が透明なまま見えなくなってしまうためです。
このリスクに関しては、透明化の際に、2秒間かけて元の表示に戻るanimationを入れる対策を入れています。
この書き換え処理になんらかのエラーが起きた場合には、元のサイトの要素が表示されるように工夫をしています。
具体的には、書き換えは次の流れになります。
- 対象の要素をCSSで
visibility: hidden;にして透明化し、2秒間かけてvisibility: visible;にするanimationを入れる - visibleになるまでの2秒間に書き換えをする
- もし、なんらかの処理上のエラーが起こり、書き換えが行われなかった場合、2秒後に元のDOMがvisibleになり、表示される。
これによって、リスクを最小化させながら、ちらつきを防止することで、ユーザー体験を向上させることができます。
書き換えが正しく行われない
書き換えが正しく行われないというリスクについても考慮しなければいけません。
たとえば、別の画像が出てしまったり、書き換えが機能せずに元サイトの画像のままになったりしている状態です。
これは、アプリケーションのバグやユーザーの設定ミス(ヒューマンエラー)によって発生することが予想できます。
アプリケーションのバグに関しては、地道なテストを書いてバグがデプロイされない仕組みを作成しています。
一方で、ユーザーの設定ミスで書き換えが正しく行われないというリスクに関しても、ユーザーの責任とはせずにサービスの提供側が考慮すべきです。
Blocksではこの点を重視し、設定によって書き換えがどのように行われるかをユーザーにフィードバックするUIを作り込んでいます。
最初に開発したのは、Chromeのextensionをいれて、実際の書き換え対象のサイトにアクセスすることによって、書き換え後の表示を確認できる仕組みです。
これによって、設定したブロックを配信することなく確認できるようになりました。
この仕組みだと、書き換えの内容をリアルタイムで確認できなかったり、管理画面を離れて別のサイトを見に行かないといけなかったりなど、ユーザーに対する負荷がありました。
このような使いづらさやユーザーのストレスは、最終的にヒューマンエラーを引き起こすと考えています。
そこで、ユーザビリティの向上目的でこのプレビュー機能を管理画面に埋め込み、リアルタイムで確認できるようにしました。
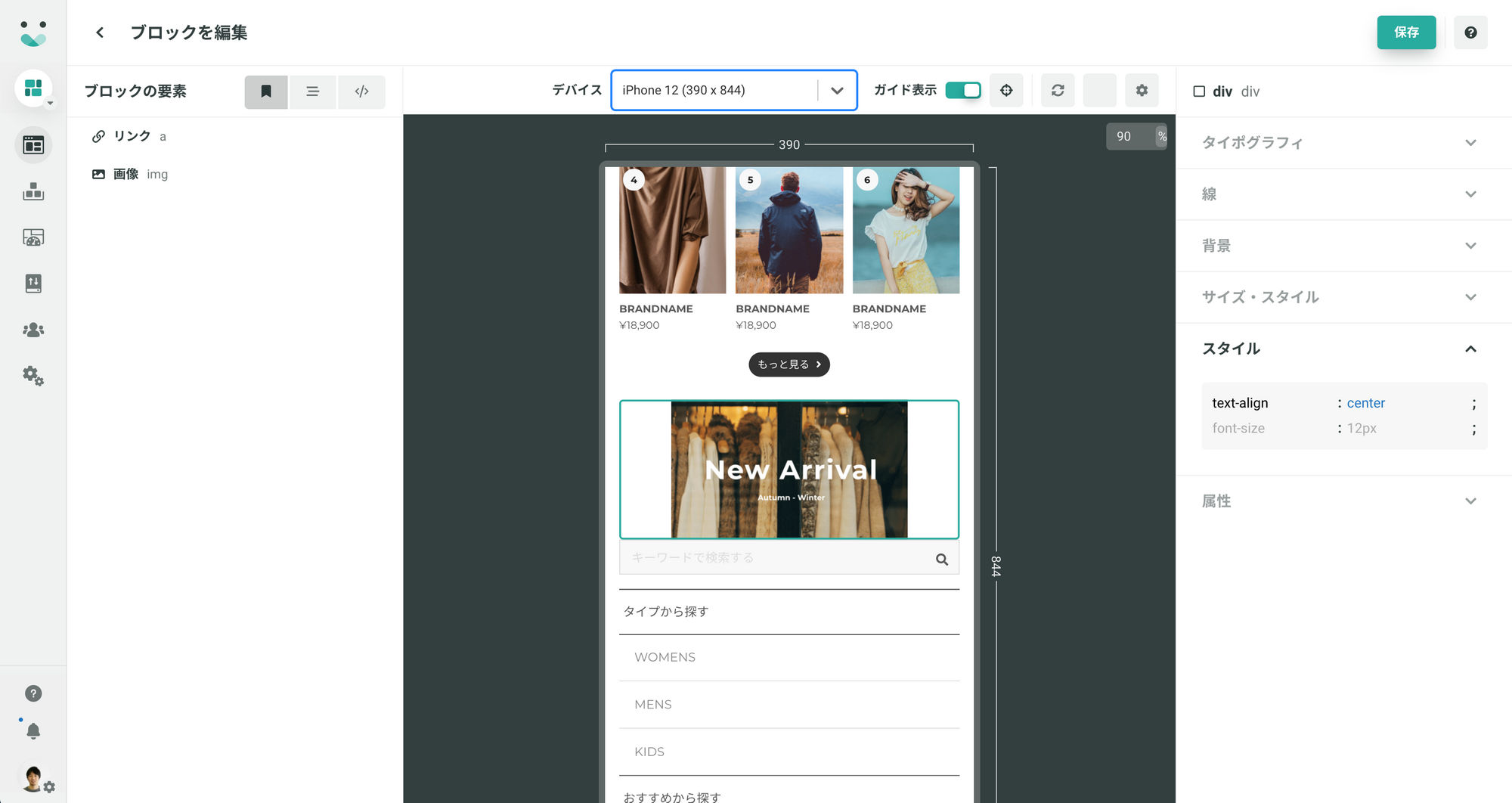
このリアルタイムプレビュー機能と同時に刷新した配信画面の新UIのおかげで、直感的に書き換える内容を確認でき、ユーザーもどう書き換えられるのかが理解しやすくなりました。
このような改善を積み重ねることによって、ユーザーの設定ミスをなくしていっています。
管理画面・拡張機能が正しく動かない
最後に、管理画面や拡張機能など、ユーザー触れる部分が正しく動かないというリスクに触れておきます。
先ほどのクライアントのサイトを部分的または全体的に壊してしまうリスクに比べると、相対的に管理画面や拡張機能などがもたらすリスクは小さいです。
これらは通常のモニタリングやテストによって、機能を保証しています。
我々はモニタリングにはDatadogを使っています。
Datadogでは次の指標などを監視して、アラートを送っています。
- builder.jsのbuildにかかった時間
- 一時間以内でbuilder.jsのbuildが失敗した数
- builder.jsから送られてくるeventのサイズ、数、勢い(突っ込まれるqueueの長さ)
- エラーログ
- Endpointへの死活監視
- Datadog APMを使ったパフォーマンス監視
- その他の異常値
基本的に、シンプルな指標をつかい、あまり解釈を入れずに異常値をアラートしています。
マルチクラウドの仕組み
さて、Blocksチームが考えているリスクの全体像と、その対応策の一部を紹介しました。
その中でも、もっともBlocksにとってクリティカルなことはbuilder.jsの配信ができなくなることです。
それに対して、BlocksではAWSとGCPでサービスプロバイダレイヤーでの冗長構成をとっています。
いくつものリスクヘッジの施策の中から、今回はこのマルチクラウドについてひとつフォーカスをして、深堀りして説明します。
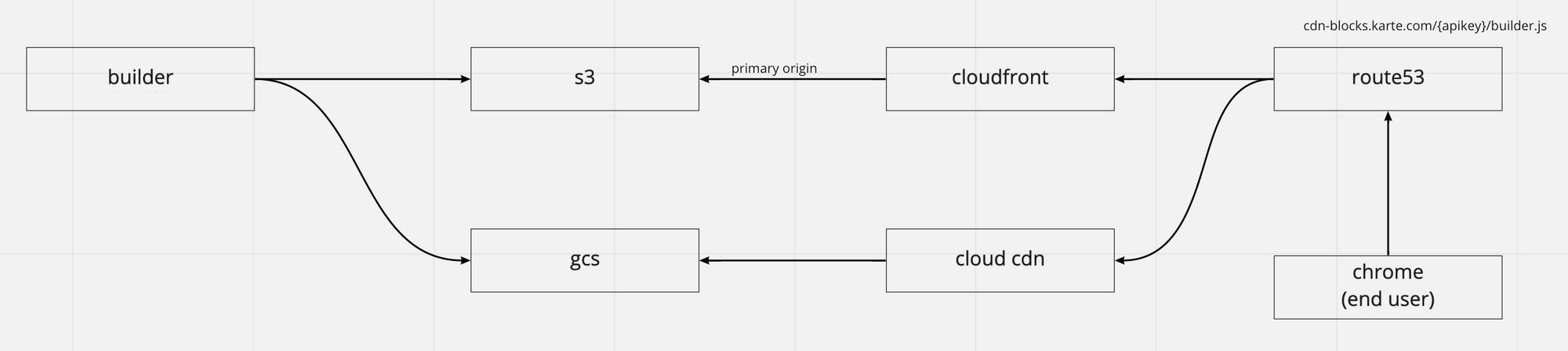
管理画面で、ブロックに関して何らかの変更して、保存をすると、builder serverがbuilder.jsを生成します。
生成されたbuilder.jsは、AWSのS3とGCPのGCSの両方にuploadされます。
通常は、クライアントのサイトに埋め込まれたscirptタグはCloudFront経由でS3にアップロードされたbuilder.jsをロードします。
もし、CloudFrontやS3に障害が起こってbuilder.jsが参照できない場合は、GCPのCloud CDNとGCSに簡単に切り替えられます。
障害時の切り替えは、Route53のTrafficFlowによって行います。
DNS トラフィックのルーティングにトラフィックフローを使用する - Amazon Route 53
Route53の設定は少し複雑なため、もう少し詳しく解説をします。

クライアントのサイトには、次のようなタグが埋め込まれています。
<script src="https://cdn-blocks.karte.io/{PROJECT_ID}/builder.js"></script>
まず、エンドユーザーはクライアントのサイトに埋め込まれているタグを読み込み、cdn-blocks.karte.ioにアクセスをします。
cdn-blocks.karte.ioはCNAMEでcdn-blocks-dual.karte.ioに名前解決されます。
cdn-blocks-dual.karte.io にはTrafficFlowによって、2つのエンドポイントに対する比重が設定されています。
具体的には、cdn-blocks-aws.karte.ioとcdn-blocks-gcp.karte.ioで、それぞれ、AWS用とGCP用のエンドポイントになります。
この2つに対するトラフィックの比重を10:0から0:10まで、刻んでトラフィックポリシーに登録しており、ポリシーレコードで、現在の比重を選択しています。
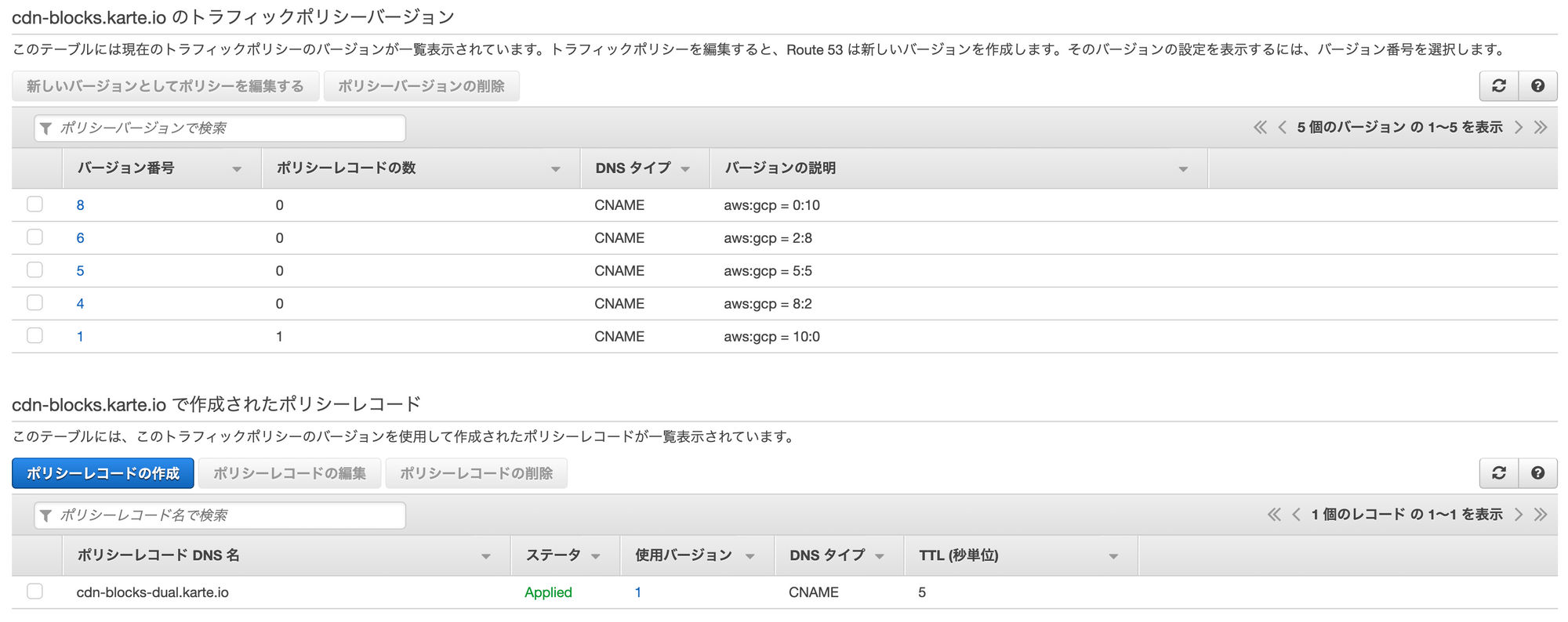
問題無い状態のときは、cdn-blocks-aws.karte.ioに100%のトラフィックが流れるようになっており、AWSに問題が起こった際に、cdn-blocks-gcp.karte.ioにトラフィックを切り替えます。
ここで重要なのが、切り替えの際にいきなり10:0から0:10に切り替えるのではなく、段階的に切り替えていくことです。
次のように、トラフィックの比重を段階的に切り替えます。
- 10:0
- 8:2
- 2:8
- 0:10
これは段階的に切り替えながら、切り替え先でトラブルが起こらないか、切り替え自体が問題なく行われるかなどを確認するためです。
実際の切り替え処理は、数分で反映されます。
CloudFrontのOrigin failoverをなぜ使っていないのか
CloudFrontには高可用性が必要なシチュエーションで使える、Origin failoverという機能があります。
プライマリオリジンが障害などで使用できない場合に自動的にセカンダリオリジンにfailoverする機能です。
builder.jsの配信の冗長性を設計する際に、こちらの機能も考慮しましたが、意図的に使わないという判断をしました。
CloudFrontのOrigin failoverを使わなかった理由は次の3つです。
- builder.jsにおける障害でもっともリスクが高いのは、CloudFrontからレスポンスが返ってこないことであり、S3に障害が発生することではない
- failoverのポイントを複数にして複雑にしたくない
- 数年に一度しか動かないようなクリティカルな仕組みをブラックボックスな自動化に頼りたくない
順番に説明をしていきます。
まず、「builder.jsの障害でもっとも怖いのはCloudFrontからレスポンスが返ってこないことであり、S3に障害が発生することではない」ということですが、前述のとおり、Blocksで一番避けなければならないリスクはクライアントのサイト全体を壊すことです。
このリスクの原因となる可能性のひとつとして、CloudFrontからのレスポンスが返ってこないというシチュエーションがあります。
CloudFrontからレスポンスが返ってこない場合、builder.jsの読み込みでクライアントのサイト全体のロードがブロックされ、画面が白くなるリスクが考えられます。
一方で、S3に障害が起こったときはどうなるでしょうか。
CloudFrontが生きていれば、エラーのレスポンスが返ってくるはずで、builder.jsは機能しないものの、クライアントのサイトは読み込まれます。
その後、アラートを見て、Route53のTrafficFlowによってGCPにfailoverすれば、builder.jsも使えるようになります。
つまり、我々がもっとも避けたいリスクは、CloudFrontのOrigin failoverでは回避できません。
「それでも、S3が利用できないシチュエーションでbuilder.jsの機能を守ることができるので、やらないよりもやるほうがよいのでは?」という疑問が浮かぶと思います。
これに関しては、Origin failoverを使わなかった残りの2つの理由によって、回答できます。
1つ目に「failoverのポイントを複数にして複雑にしたくない」という理由があります。
上図のとおり、Route53でGCP/AWSのfailoverがあり、加えてCloudFrontでのfailoverも入れてしまうと、ユーザーへ配信されるbuilder.jsに3つのパターンができてしまいます。
cdn-blocks.aws.karte.io→ CloudFront → S3cdn-blocks.aws.karte.io→ CloudFront → GCScdn-blocks.gcp.karte.io→ Cloud CDN → GCS
さらにそれぞれのパターンで経由するポイントをなどまで考慮すると、障害時に調査する複雑性が上がってしまいます。
たとえば、builder.jsが読み込まれないとなったときに、どこが問題なのか、failoverはうまく動いているのか、そもそもどこでfailoverされているのかなど、状況の把握により多くのコストがかかると考えられます。
また、「数年に一度しか動かないがクリティカルな仕組みをブラックボックスな自動化に頼りたくない」という理由も存在します。
ほとんど動かない仕組みを自動化してしまうと、いざ動かなかったときのリスクが高いです。
おそらく数年に一度しか動かない仕組みは、手動で結果を確認しながら動かしたくなるはずです。
シンプルで把握しやすく、確実に動かせるように設計しました。
KARTEのマルチクラウド事例
さて、実はこのマルチクラウドではうまく動いている事例がすでに社内にあります。
KARTEでは数年以上前からマルチクラウドを採用しており、実際に多くの障害時に実績をあげてきました。
今回の記事では詳しく書きませんが、次の記事内の発表スライドが参考になります。
Google Cloud Day: Digital で Anthos と ML について話してきました
私は、Blocksのプロジェクトを開始する前までは、SREチームでKARTEの解析エンジンなどの運用もやっていました。
その中で、いまでも覚えている、マルチクラウドの強力さを体感したエピソードを共有します。
私がSREチームに入ってすぐの頃に、GCPのロードバランサに大規模な障害が起こり、早朝にアラートがなりました。
そこから、slackを立ち上げると、チームメンバーがすでに原因の調査に取り掛かっており、ロードバランサ周りがあやしいと数分で結論づけていました。
すぐにslackのhubotにコマンドを投げると、数分で解析エンジンのインフラがGCPからAWSに切り替えられ、アラートがなってから数分以内でサービスレベルではまったく問題ない状況に戻っていました。
このときの障害はロードバランサが死んだこともあり、影響が大きく、世界中で数億人が使っているゲームやコミュニケーションサービスなどが40分以上にもわたって使えない状態となり、大きなニュースになったことを覚えています。
KARTEは数分で復旧しており、クライアントからの指摘も来ないレベルでした(当然、障害レポートは出してクライアントに伝えています)。
前職では社内IaaSで開発をしていたため、「バランサが落ちても数分で復旧できるのか」とマルチクラウド構成に衝撃を受けたのを覚えています。
そこから2年ほどKARTEの運用で学んだこととして「AWS/GCPといえども、落ちるときは落ちる」ということがあります。
何度もAWS/GCPの切り替えを経験しました。
自分たちでサーバーを運用するよりも遥かに可用性が高いはずですが、過信してはいけません。
ミッションクリティカルな部分であれば、GCP/AWSの冗長構成は考慮すべきだと考えています。
終わりに
この記事ではBlocksで考えているリスクについて説明し、リスクヘッジの一部を解説しました。
その中でもひとつ、マルチクラウドを掘り下げて説明しました。
まだまだ、この記事で触れていない部分も多いので、もし興味がある方がいれば、気軽にコンタクトをとってください。
この記事は「KARTE Blocksリリースの裏側」の4日目の記事です。全10回を予定しています。
これから毎日記事を更新していくため、更新をチェックしたい方は@KARTE_BlocksのTwitterアカウントをフォローしてください!
最後に、KARTE Blocks自体の開発に興味がある!というエンジニア(インターンも!)を募集しています!
詳しくは弊社エンジニア採用ページや採用スライドをご覧ください!