
Google Cloud Japan Blog で Anthos clusters on AWS を活用した事例が紹介されました
Posted on
エンジニアの大矢です。
本日、Google Cloud Japan Blog で「Anthos clusters on AWS を活用し、マルチクラウドでもGKE 由来の高度なマネージド環境を享受」というタイトルで弊社の事例が紹介されました。
私たちがどのような背景でマルチクラウド構成を採用するに至ったか、どのような狙いで Anthos clusters on AWS を導入したかについて書かれていますので、ぜひ読んでみてください。また、細かいアーキテクチャの変遷について気になった方はこちらの記事にある動画も合わせて見ていただけると幸いです。
この記事ではもう少し細かく、実際どう運用しているかや注意するポイントなどを書いています。
Anthos clusters on AWS を活用したアーキテクチャ
まずはじめに、Anthos clusters on AWS を導入することでどのようなアーキテクチャになったかを簡単に説明します。
KARTE には大きく分けて2つのサーバ群があり、解析基盤(Track/Analyze)と管理画面(Admin)に分かれています。下図のように今回 Anthos clusters on AWS を採用したのは Admin の方で、Route53 Traffic Flow を利用してアクセスを振り分けています。通常時には、ほぼ全てのリクエストが GKE[1] 側にルーティングされるようになっており、AWS 側では GKE で動いてるものと同じワークロードがデプロイされ、停止した状態になっています。
また Anthos clusters on AWS には、専用の VPC 内にクラスタを作成する方法と、既存の VPC にクラスタを作成する方法がありますが、図のように既存の VPC 内にある EC2 で動く mongoDB にアクセスできる必要があったため、既存の VPC に作成しました。
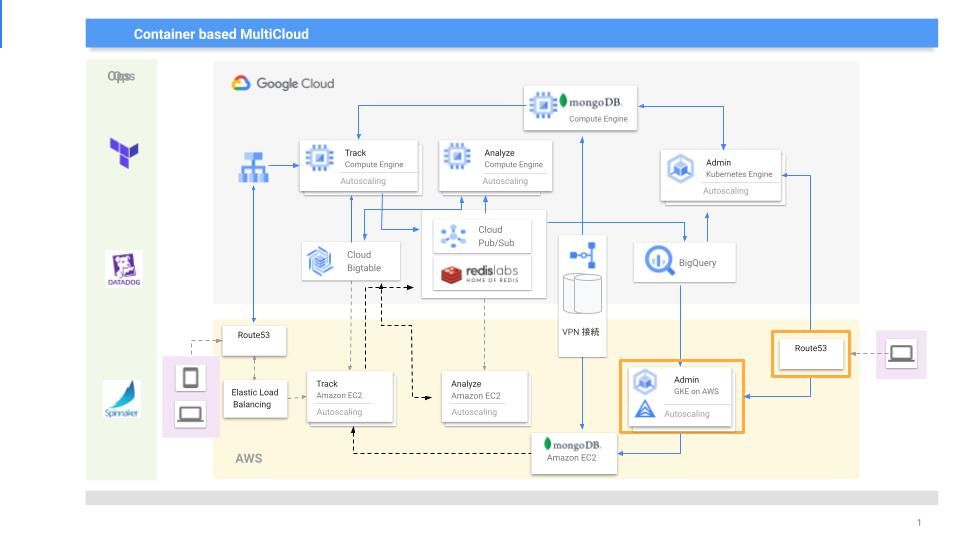
また、管理画面で発生するほぼ全てのリクエストは GKE 側にルーティングされると書いたのですが、実は管理画面のコンポーネントのいくつかは Anthos clusters on AWS がメインとして動いており、その一つは KARTE 管理画面上で接客を編集する際にプレビューするための Proxy サーバになります。
この Proxy サーバは元々 EC2 で動いており、サブドメインが動的に作られるため、AWS Certificate Manager(ACM) のワイルドカード証明書を利用していました。管理画面が GKE で動くようになった後、Proxy サーバも GKE に移行したかったのですが、GCP ではマネージドなワイルドカード証明書が利用できず、移行するにはセルフマネージド証明書の管理が必要でした。そのため、Proxy サーバを Anthos clusters on AWS 上でのみ動かすことにして、ACM のワイルドカード証明書をそのまま利用しています。
このように AWS の機能を利用した方が管理が楽になったり、AWS にしかないような特徴を持つサービスを使いたい、となったときに簡単に AWS 上で Kubernetes を動かすことができます。
マルチクラウド Kubernetes 運用のポイント
今回 Anthos clusters on AWS を導入しマルチクラウド運用にする際に考慮したポイントは、運用にかかるコストを極力減らすことです。Anthos clusters on AWS では、Connect という機能を使うことで GKE の管理画面で AWS 上にあるクラスタを同じように管理できるなど、AWS 上のクラスタも同じように扱える仕組みがあります。
しかし、いくつか注意点もあります。secret の管理もその 1 つですが、既に記事を書いてる[2]のでここには書きません。下記の 4 つについて、どのようにして運用しているかを説明します。
- デプロイ
- manifest の管理
- Ingress
- 監視
pull 型のデプロイ
GitOps では push 型と pull 型の 2 つのパターンがあります。push 型は kubernetes クラスタ外にある CI システム上で スクリプトを実行することによりデプロイします。pull 型は kubernetes operator がクラスタの内部からデプロイをします。
Anthos clusters on AWS はプライベートクラスタを構成するため、VPC 内のインスタンスからでないとデプロイを実行できません。
push 型のデプロイシステムを採用していた場合は VPC 内に CI システムを置くか、VPC 内にある踏み台サーバに対して ssh tunnel を貼る必要がありました(現在はベータ版の Connect Gateway を使うことで VPC の外からでも kubectl を使うことができます)。
私たちは pull 型のデプロイツールである ArgoCD を採用していたため、GKE にデプロイするのと同じように AWS にもデプロイすることができます。具体的には、ArgoCD の Application の設定ファイルを1つ書き加えるだけで、AWS のデプロイフローを整えることができました。
Kustomize を利用した manifest の管理
マルチクラウドに限った話ではないですが、複数環境の差分を管理するためのツールとして Kustomize はとても便利です。
冒頭に書いたように、Active/Standby 構成のため AWS にも GKE と同じものデプロイしていますが、ほとんどのワークロードは停止しています。また、GKE で利用してる一部のリソースやワークロード(BackendConfig や custom-metrics-stackdriver-adapter)はそのまま使うことはできません。
共通の部分は同じ manifest を使いつつ、環境ごとにパラメータを変えたり Active/Standby 構成を実現するために、Kustomize を利用しています。
例えば、全ての Deployment と CronJob を止めるために、下記のようなパッチを使っています。
- op: replace
path: /spec/suspend
value: true
- op: replace
path: /spec/replicas
value: 0
patches:
- path: path/to/cronjob-suspend.yml
target:
kind: CronJob
- path: path/to/replicas-zero.yml
target:
kind: Deployment
このようにすることで、新しく追加したワークロードが AWS 上で意図せず動いてしまう心配もないですし、仮に GCP 側で障害が起こり待機系に切り替えなければいけなくなった際には、このパッチを外してデプロイするだけで GKE と同じように全てのワークロードが立ち上がります。
Ingress
Anthos clusters on AWS では Classic Load Balancer, Network Load Balancer および Application Load Balancer(ALB)が利用できます。私たちは L7 Load Balancer を使う必要があったので ALB を利用しました。
ALB を利用するためには AWS Ingress Controller をインストールしたり、サブネットにタグをつけたりする必要がありましたが、ドキュメントに手順が詳しく書いていたため導入まではスムーズに進むことができました。
注意する必要があるのは、GCP の Cloud Load Balancer と ALB ではパスベースルーティングにおけるルールの評価方法が異なることです。Cloud Load Balancer ではワイルドカードが指定でき、複数のルールにマッチする場合はより限定されたルールの方に従います。ルールの定義順はルーティングに影響しません。例えば下記のような spec を持つ Ingress によって生成された Cloud Load Balancer があり、http://example.com/hoge/123 にリクエストを送ると、2番目のルールが適用されて hoge service にルーティングされます。
spec:
rules:
- host: example.com
http:
- path: /*
backend:
serviceName: default
servicePort: 80
- path: /hoge/*
backend:
serviceName: hoge
servicePort: 80
- path: /huga/*
backend:
serviceName: huga
servicePort: 80
しかし、上記の spec の Ingress から生成された ALB では http://example.com/hoge/123 にリクエストを送ると default service にルーティングされます。
これは、ALB ではルールの評価が上に定義されたものから順に行われ、マッチした時点でそのルールが適用されるためです。下記のように/* のルールを一番下に書くことでこの問題を回避し、GKE と AWS で同じ Ingress の manifest を利用できました。
spec:
rules:
- host: example.com
http:
- path: /hoge/*
backend:
serviceName: hoge
servicePort: 80
- path: /fuga/*
backend:
serviceName: fuga
servicePort: 80
- path: /*
backend:
serviceName: default
servicePort: 80
監視
監視についてもいくつか選択肢があります。オープンソースの Logging Agent および Monitoring Agent を追加でインストールすることで、Cloud Logging, Cloud Monitoring が利用できます[3]。
私たちは元々マルチクラウドを構成を採用していたため、全ての監視を Datadog に集約していました[4]。そのため、Anthos clusters on AWS の監視についても Datadog を採用しました。既に GKE でも Datadog を利用していたため、同じように datadog-agent などのコンポーネントをデプロイする[5]だけで簡単にロギング・モニタリングを実現できました。
最後に
Anthos clusters on AWS を利用することで、運用コストを余計にかけすぎることなく、高可用性や AWS サービスの活用を実現しました。
今後はさらにマルチクラウドの特性を活かして、新たな価値を生み出していきたいです。
CX(顧客体験)プラットフォーム「KARTE」を運営するプレイドでは、KARTEを使ってこんなアプリケーションが作りたい! KARTE自体の開発に興味がある!というエンジニア(インターンも!)を募集しています。
詳しくは弊社採用ページまたはWantedlyをご覧ください。 もしくはお気軽に、下記の「話を聞きに行きたい」ボタンを押してください!
Anthos clusters on AWS も GKE ではありますが、この記事では Google Cloud 側の GKE のことを単に GKE、AWS 側の GKE のことを on AWS と書いています。 ↩︎
悩みに悩んだ Kubernetes Secrets の管理方法、External Secrets を選んだ理由 | PLAID engineer blog を読んでいただけると幸いです。 ↩︎
私たちが Datadog をどのように活用しているかより詳しく知りたい場合はこちらの記事を是非読んでみてください。 ↩︎